Concrete Crack Classification Tutorial (pytorch)
はじめる前に
このチュートリアルを始める前に、以下の KAMONOHASHI のインストールが終わり、KAMONOHASHI にログインできることを確認してください。
はじめに
本チュートリアルでは、KAMONOHASHI を使用して、大量のデータを用いてコンクリート画像のヒビの有無を検出するモデルを作成し学習する方法を以下の手順に沿って説明します。
- データをアップロードする
- データセットを作成する
- 学習を実行する
- TensorBoard で学習の状況を表示する
- 学習のログを確認する
データをアップロードする
KAMONOHASHI にデータをアップロードする流れを説明します。
concrete データセットを準備する
このチュートリアルでは、Concrete Crack Images for Classification[2]launchを使用します。
Concrete Crack Images for Classification のデータをダウンロードするsave_alt
Concrete Crack Images for Classification は、カラー画像のデータセットです。 このデータセットは解凍すると、
- Positive
- Negatvie
の 2 ディレクトリに分かれており、それぞれ 20000 枚のデータが含まれています。
そのうち 15000 枚*2 を学習データ、5000 枚 *2 をテストデータとしてまとめて zip 化します。
- train.zip(Positive 15000 枚, Negative 15000 枚)
- test.zip(Positive 5000 枚, Negative 5000 枚)
KAMONOHASHI へのデータのアップロードの前にそれぞれのクラスのファイル名の先頭にクラスの頭文字(P または N)をつけ、あとでラベル付けを行いやすいようにしておきます。
データを KAMONOHASHI にアップロードする
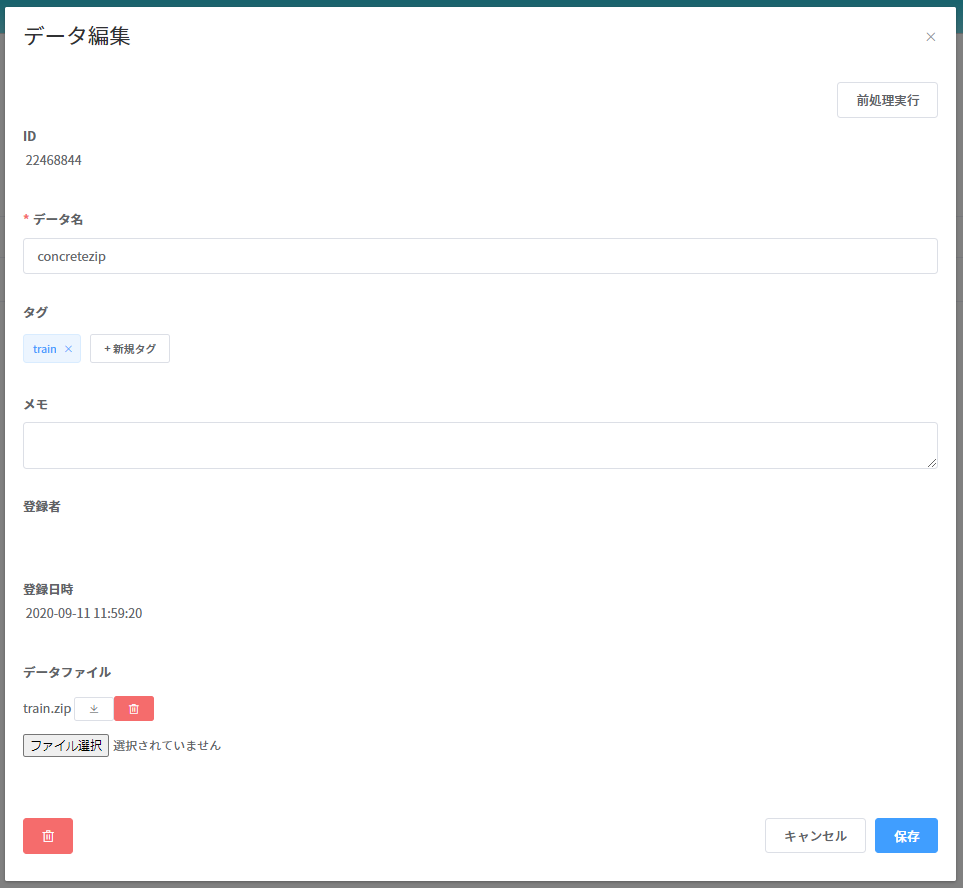
データが用意できたら KAMONOHASHI にアップロードしましょう。 [データ管理]を選択し、右上の新規登録ボタンから行います。
| 種類 | 説明 |
|---|---|
| データ名 | (例)train.zip |
| メモ | 画像の説明など補足情報。 |
| タグ | データの種類や受領日などグルーピングしたい単位に付与し、検索等で利用する。 |
| ファイル | 複数のデータを登録できる。jpg/png/csv/zip など、ファイルのデータ形式は任意。 |
上記の情報を入力し、右下の登録ボタンを押すとデータをアップロードすることができます。 コマンドラインインターフェイス(CLI)を使用してデータをアップロードすることも可能です。
KAMONOHASHI では、複数のファイルを一つのデータとして管理可能ですが、今回は個別に、一ファイル一データとして登録します。
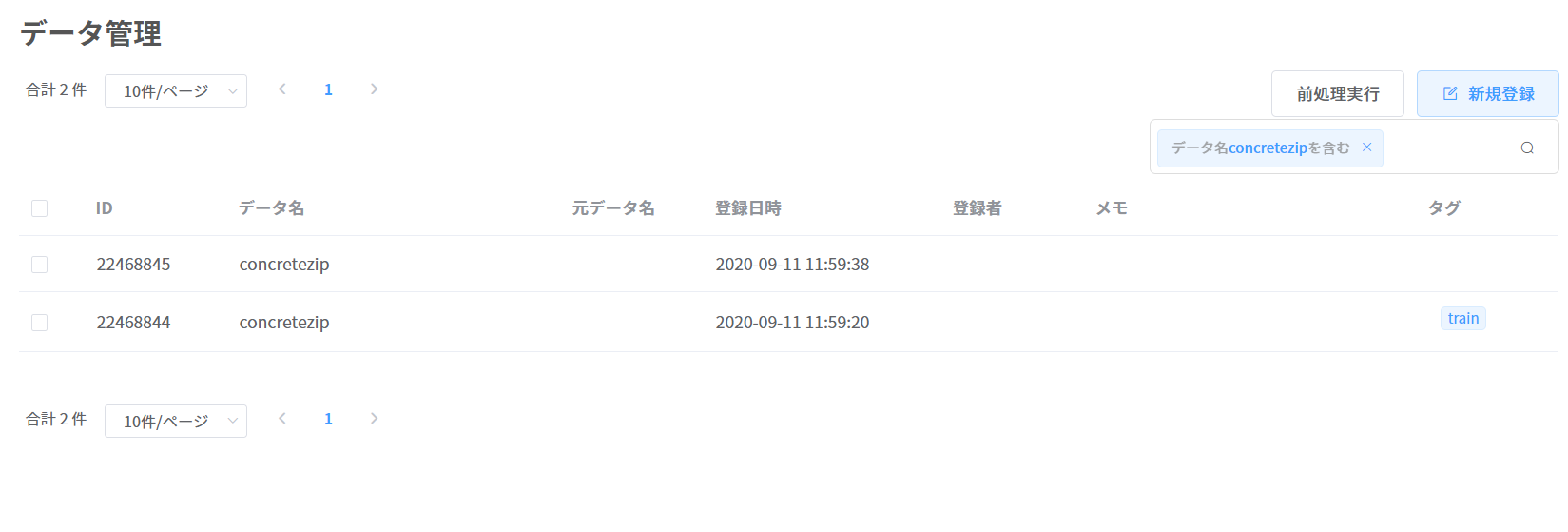
登録したデータは、データの一覧画面で確認できます。
データセットを作成する
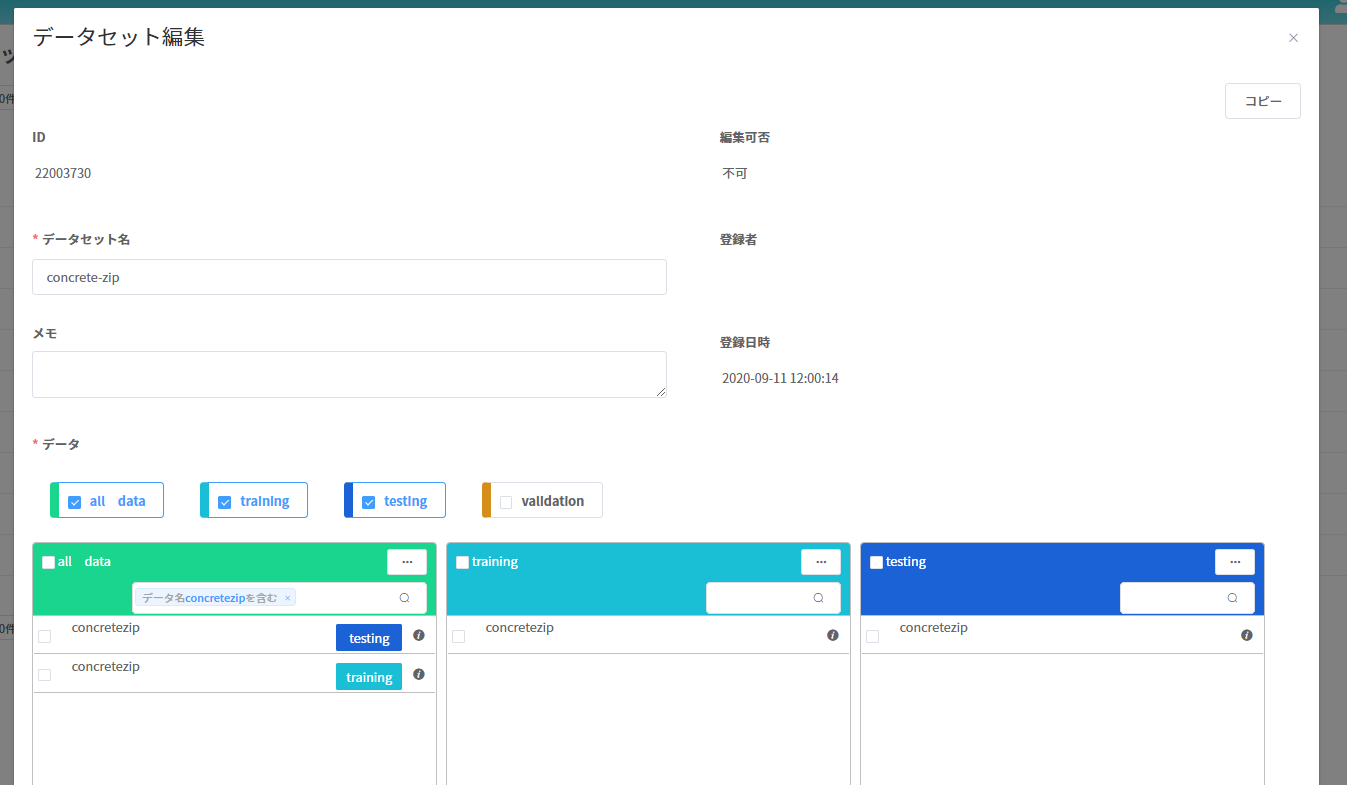
[データセット管理]を選択し、右上の新規登録ボタンから行います。 アップロードしたデータを training 用、test 用にまとめます。 下図では、train.zip を training、test.zip を testing に移動させています。
学習を実行する
学習は KAMONOHASHI が管理するクラスタで計算を実行するための最小単位を表します。 学習を開始すると KAMONOHASHI はクラスタから指定された CPU、メモリ、GPU リソースを確保し、Docker コンテナを起動し計算環境を用意します。ユーザはこの環境を利用し、任意の計算を行うことができます。 学習は CLI、GUI の両方から起動できます。 GUI で学習を開始するには[学習管理]を選択し、新規登録ボタンから行います。 詳細はUser Guideを参照してください。
また、学習ではなく notebook 形式で進める場合はこちらから notebook を確認できます。 User Guide ノートブック管理やnotebook のチュートリアルを参照してください。
step1
学習名を記入し、先ほど登録したデータセットを選択します。 半角英数小文字、または記号(“-”(ハイフン)) 30 文字以下で指定可能です。
step2
フレームワークとモデルをテキストエリアに記述し、実行コマンドを記述します。 本チュートリアルではフレームワークはDocker Hubの公式イメージ(pytorch/pytorch)を使用しています。
- コンテナイメージ
| コンテナイメージ | 記述例 |
|---|---|
| レジストリ | officail-docker-hub(選択) |
| イメージ | pytorch/pytorch |
| タグ | 1.3-cuda10.1-cudnn7-runtime |
※Docker Hub を指定した後イメージ、タグをテキストエリアに入力してください。
- モデル のサンプルコード
| モデル | 記述例 |
|---|---|
| Git サーバ | GitHub(選択) |
| リポジトリ | KAMONOHASHI/tutorial |
| ブランチ | master |
※GitHub を指定した後リポジトリ、ブランチをテキストエリアに入力してください。
- 実行コマンド例
apt-get update
apt-get install unzip
unzip /kqi/input/training/*/train.zip -d "/kqi/input/training"
unzip /kqi/input/testing/*/test.zip -d "/kqi/input/testing"
python -u pytorch/concrete-classfication/train.py \
--train_log_dir /kqi/output/demo \
--parameter_dir /kqi/output/demo \
--max_steps=3000 \
--epochs=3
step3
必要なリソースを指定します。 以下は例です。
例
| リソース | 使用量 |
|---|---|
| CPU | 8 |
| Memory | 8 |
| GPU | 1 |
step4
オプションとして追記したい項目があれば追記し実行ボタンを押します。
ステータスが Running になったら学習中です。 初回起動の場合は、Docker コンテナを DockerHub から pull する必要があるため、学習の開始までに少し時間がかかります。
学習の状況を確認する
Tensorboard で学習の状況を確認する
実行した学習を選択し、学習履歴画面を開きます。
Tensorboard の起動ボタンを押し、開きます。
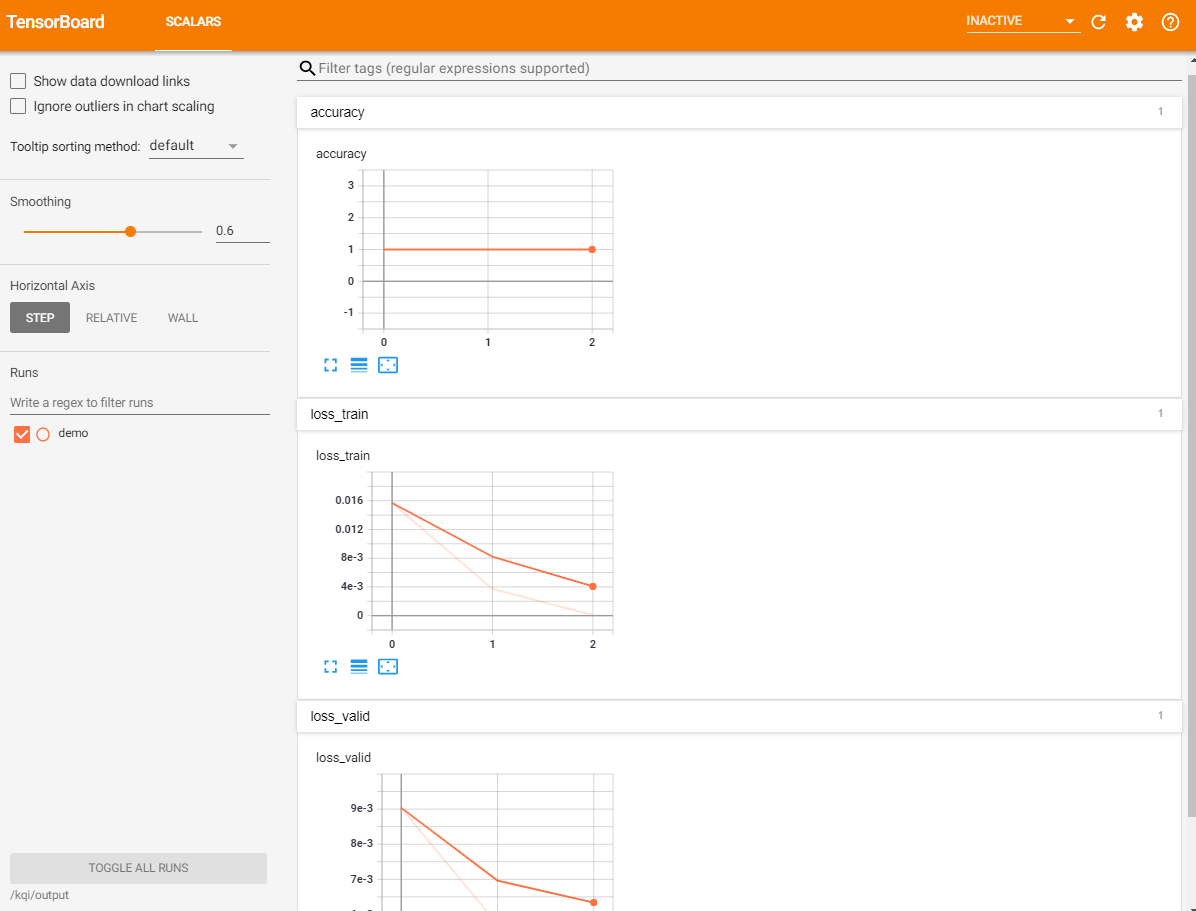
注意:TensorBoard を表示する場合、モデルの python ファイル中に対応するプログラムを書く必要があります。
学習の標準出力を確認する
学習実行中でも標準出力をダウンロードして確認することができます。
GUI からは添付ファイル欄にあるログファイル閲覧ボタンを押すとブラウザ上で標準出力を確認することができます。
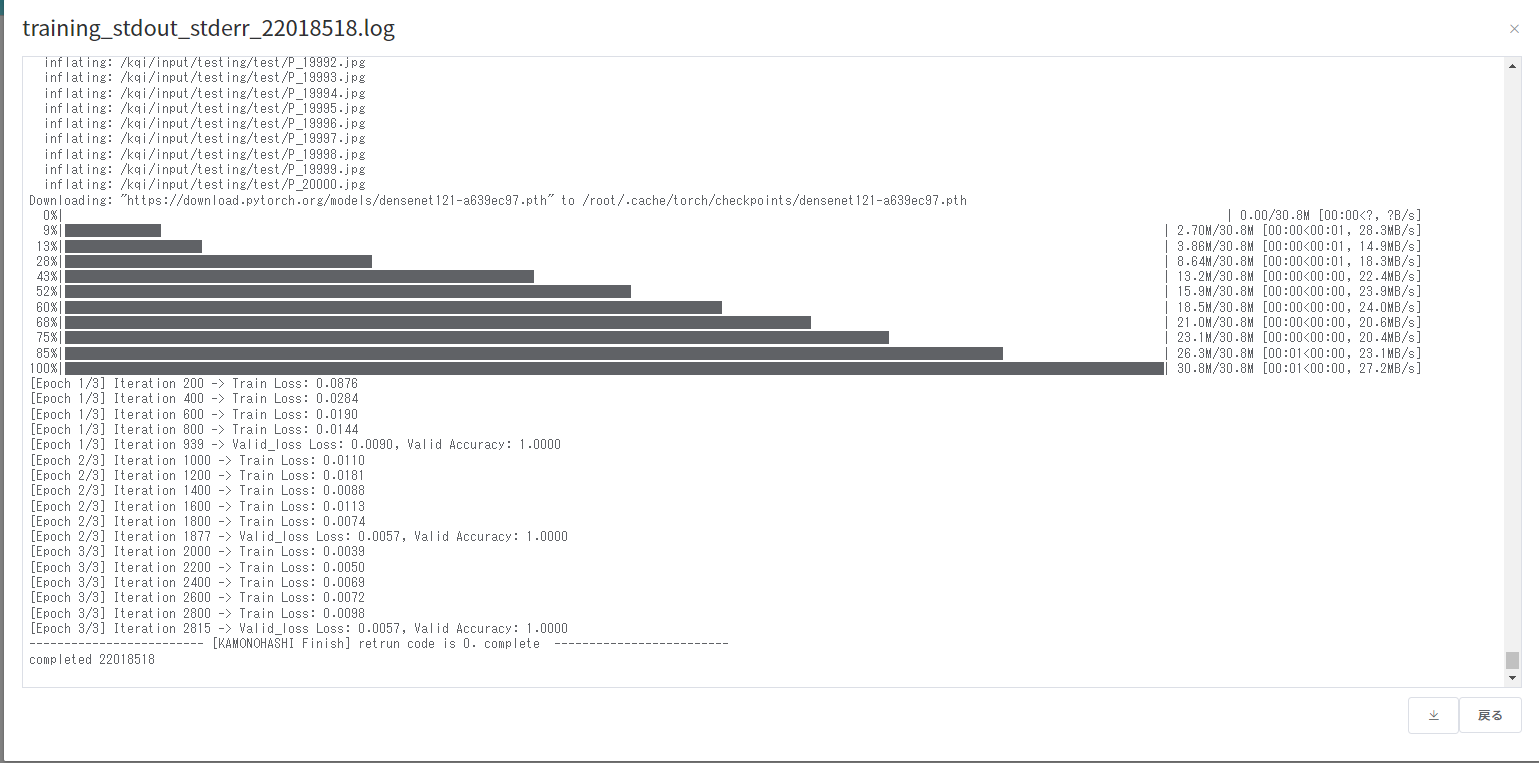
標準出力は学習履歴画面からダウンロードすることもできます。
学習の正常終了を確認する
学習が正常に終了すると、ステータスが Completed になります。
学習履歴画面のファイル一覧ボタンを押すと コンテナに出力したファイルを確認することができます。
今回は epoch 数を 3 としたため、3epoch 終了後に checkpoint(.pth ファイル)が出力されていることが確認できます。 上述した標準出力をみることでも、学習の正常終了を確認することができます。
おわりに
このチュートリアルでは、KAMONOHASHI を用いて、コンクリートのひびを検出するモデルを作成し、 GPU ノードを用いて転移学習を行いました。 特に、大量のデータを扱う際の参考になれば幸いです。
実際の現場では本チュートリアルのように異常画像が豊富にないケースがあるかもしれません。 そういった際にはより試行錯誤が必要になります。 KAMONOHASHI を活用して学習の試行錯誤とデータの管理を同時にできるため、効率的な AI 開発フローを実現しましょう。
より詳しく KAMONOHASHI の使い方を知りたい場合はHow-to Guideを参照してください。
参考文献・データセット
- [1] Zhang, Lei, et al. “Road crack detection using deep convolutional neural network.” 2016 IEEE international conference on image processing (ICIP). IEEE, 2016.
- [2] Özgenel, Çağlar Fırat (2019), “Concrete Crack Images for Classification”, Mendeley Data, V2, doi: 10.17632/5y9wdsg2zt.2 (https://data.mendeley.com/datasets/5y9wdsg2zt/2)